© 2023 yanghn. All rights reserved. Powered by Obsidian
4.2 多层感知机的从零开始实现
要点
- 这里的从零开始指的是自己完成参数,模型,激活函数定义
- 输出层神经元个数,和分类类别是一致的
1. 初始化模型
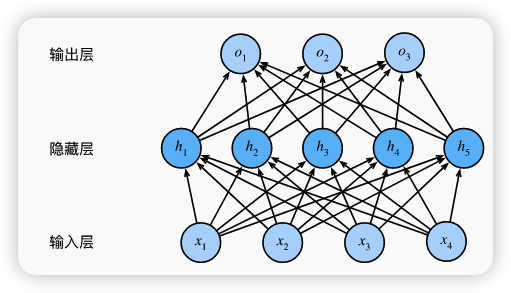
具有一个隐藏的网络架构
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
参数维度:
:(784, 256) : (256,) : (256,10) : (10,)
注意:这里与内置的 `nn.linear` 参数是互为转置的
在许多机器学习和数学文献中, 线性变换通常是以列向量形式的输入
结论:
nn.Linear 的参数形状是 (out_features,in_features),满足
2. 激活函数
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
3. 定义模型
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
return (H@W2 + b2)
4. 损失函数
交叉熵损失:
loss = nn.CrossEntropyLoss(reduction='none')
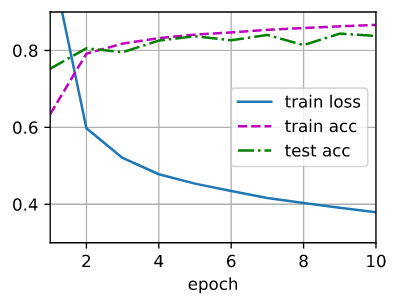
5. 训练
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
d2l.train_ch3 参考: