© 2023 yanghn. All rights reserved. Powered by Obsidian
6.5 汇聚层(pooling)
要点
- 汇聚层(池化层)返回窗口中的最大或者平均,不改变通道数
- 用来减少对像素点位置的敏感性(对像素的过拟合)
- 和卷积层一样,同样有窗口大小、填充、步幅为超参数
- 现在用的比较少,原因是有数据增强减少像素敏感性
卷积层对图像当前位置过于敏感,当当前像素发生一点变化时,图片与卷积的结果就会发生变化,对于图像边缘有点过拟合,汇聚(pooling)层的目的就是通过采样的方式,减少这种敏感性
1. 最大汇聚层和平均汇聚层
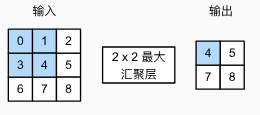
- 池化层不改变通道个数,对每个通道都单独使用
# 手动实现 pooling 计算
import torch
from torch import nn
from d2l import torch as d2l
def pool2d(X, pool_size, mode='max'):
p_h, p_w = pool_size
Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + p_h, j: j + p_w].max()
elif mode == 'avg':
Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
return Y
2. 填充和步幅
与卷积层一样,汇聚层也可以改变输出形状。都有填充和步幅的概念,例如:
X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4))
X
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]]]])
直接用框架的汇聚层:
pool2d = nn.MaxPool2d(3) # 默认步幅大小与池化层 size 大小一致,这样可以保证不重叠
pool2d(X)
tensor([[[[10.]]]])
也可以手动指定填充和步幅:
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)
tensor([[[[ 5., 7.],
[13., 15.]]]])
而对于多个通道,汇聚层在每个输入通道上单独运算,而不是像卷积层一样在通道上对输入进行汇总。 (torch.cat 不改变维度,参考 6.4 多输入多输出通道#^97d15f)
X = torch.cat((X, X + 1), 1)
X
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]],
[[ 1., 2., 3., 4.],
[ 5., 6., 7., 8.],
[ 9., 10., 11., 12.],
[13., 14., 15., 16.]]]])
进过 pooling layer 之后也不改变维度:
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)
tensor([[[[ 5., 7.],
[13., 15.]],
[[ 6., 8.],
[14., 16.]]]])
为什么池化层用的越来越少
沐神理解:
- 池化层的作用就是为了降低像素敏感,而现在有很多数据增强的方法(对图像进行旋转,平移一点),从数据层面减少了像素点的过拟合
- 池化层另一个目的就是设计步幅来减少计算量,但这个任务卷积层也可以做到,现在算力也足够,所以池化层用得少