© 2023 yanghn. All rights reserved. Powered by Obsidian
7.4 含并行连结的网络(GoogLeNet)
要点
- Inception 块用 4 条不同超参数的卷积层和池化层的路来抽取不同信息
- 每用一次 Inception,图像大小不变,通道数增加
- 主要是优点是模型参数小,计算复杂度低
- GoogLeNet 用了 9 个 Inception 块,第一个达到上百层网络(不是上百层深,通道是并行的)
- 过于复杂是一个最大的缺点
在2014年的 ImageNet 图像识别挑战赛中,一个名叫_GoogLeNet_ (Szegedy et al., 2015)的网络架构大放异彩。其主要思想是结合了各种卷积结构的优势
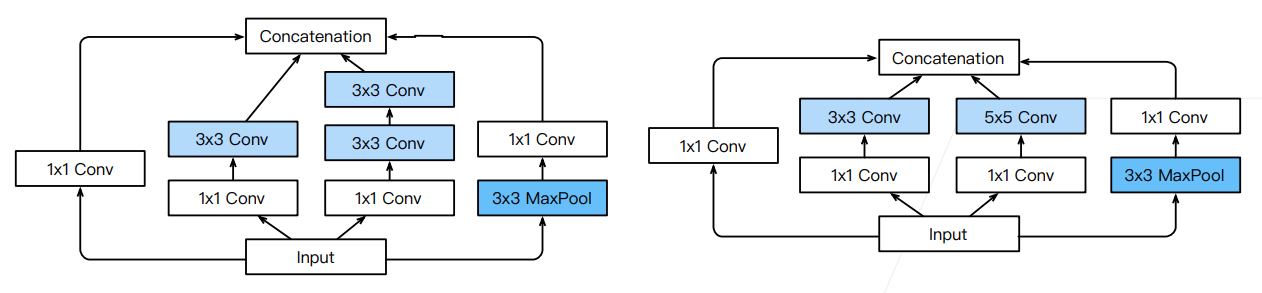
1. Inception 块
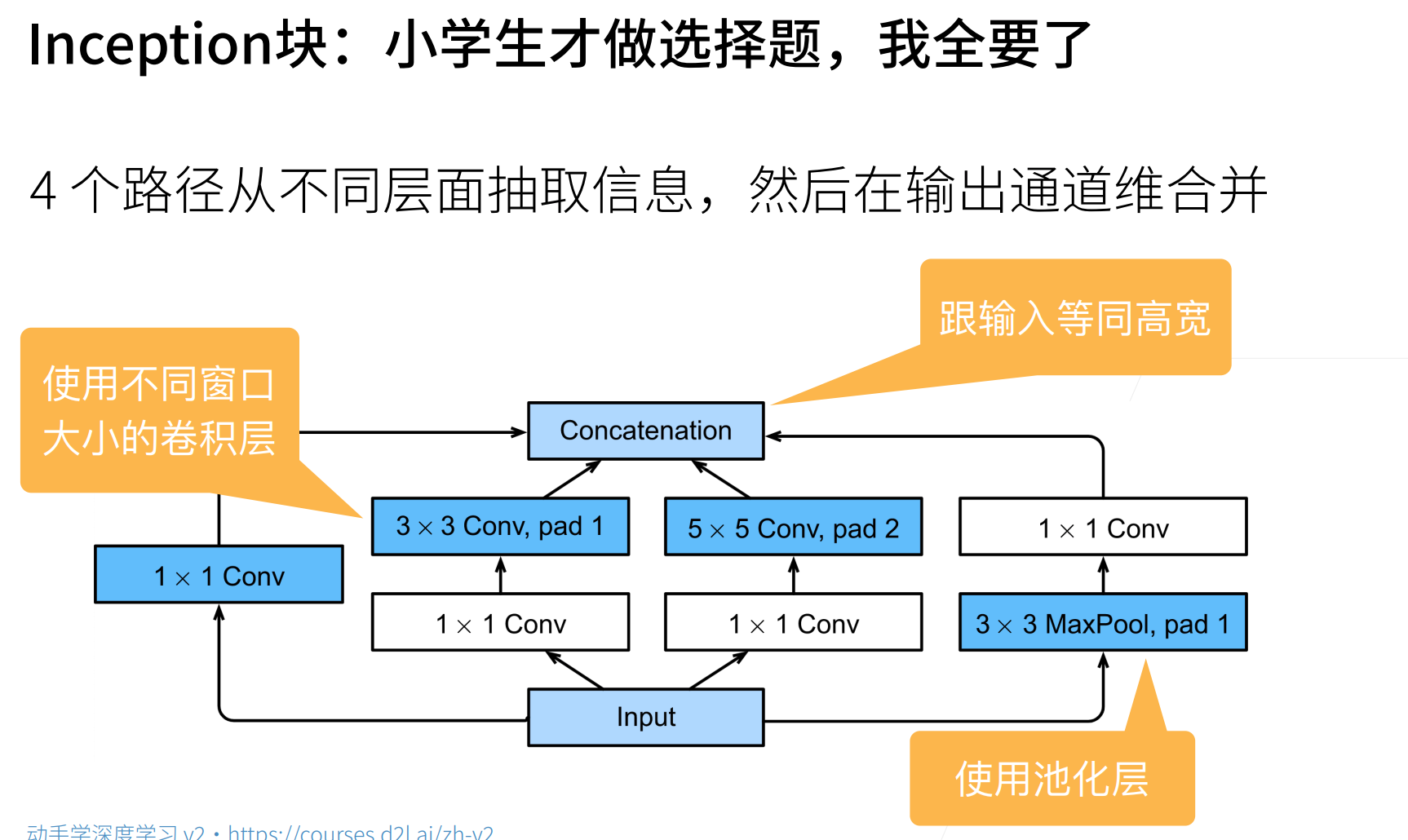
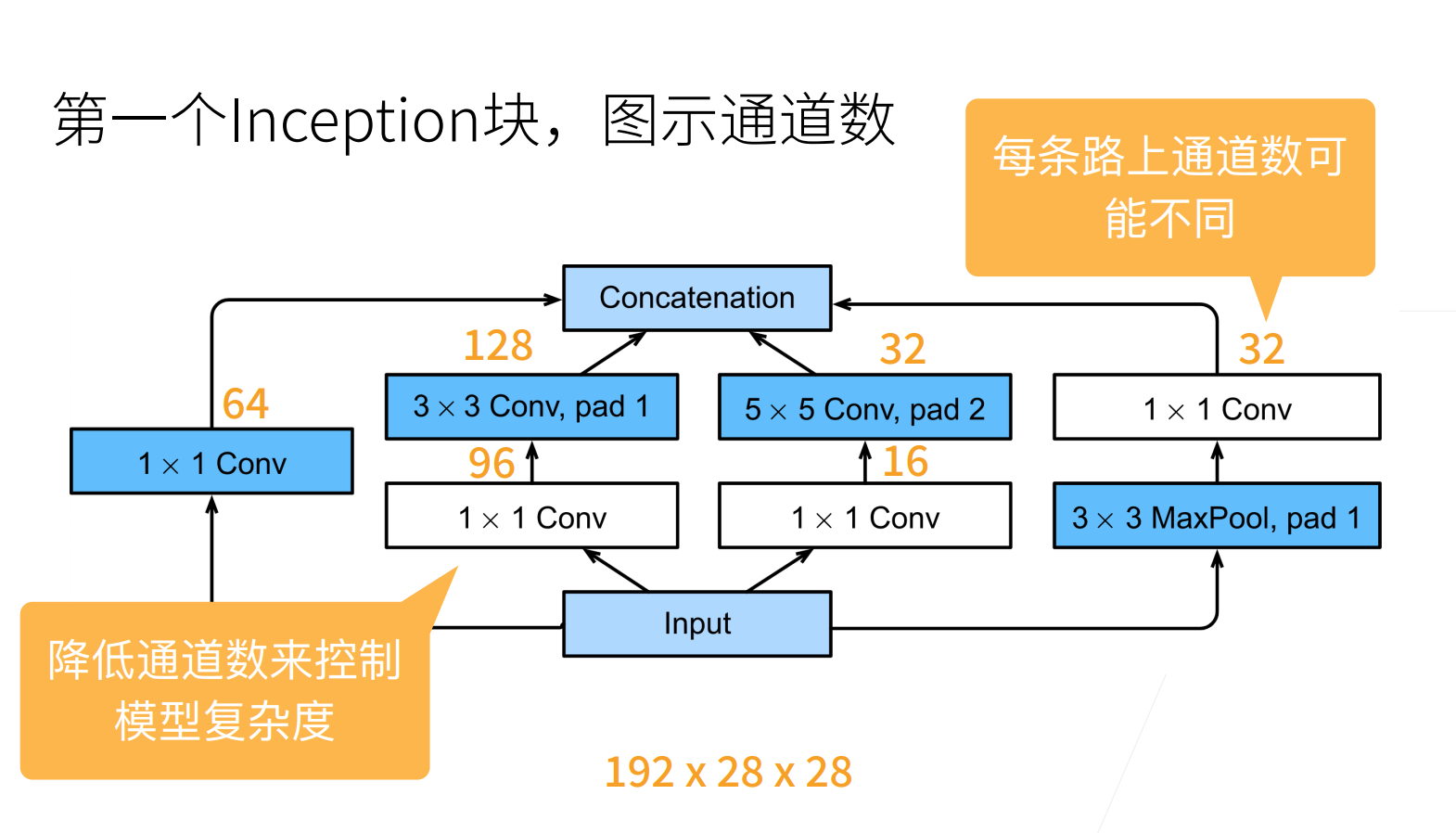
- 文章并没有说这些 64、128、32 等是怎么来的,大概率是调出来的
- 最后是将通道堆叠在一起,得到一个 256 的通道(64+128+32+32=256)
跟单
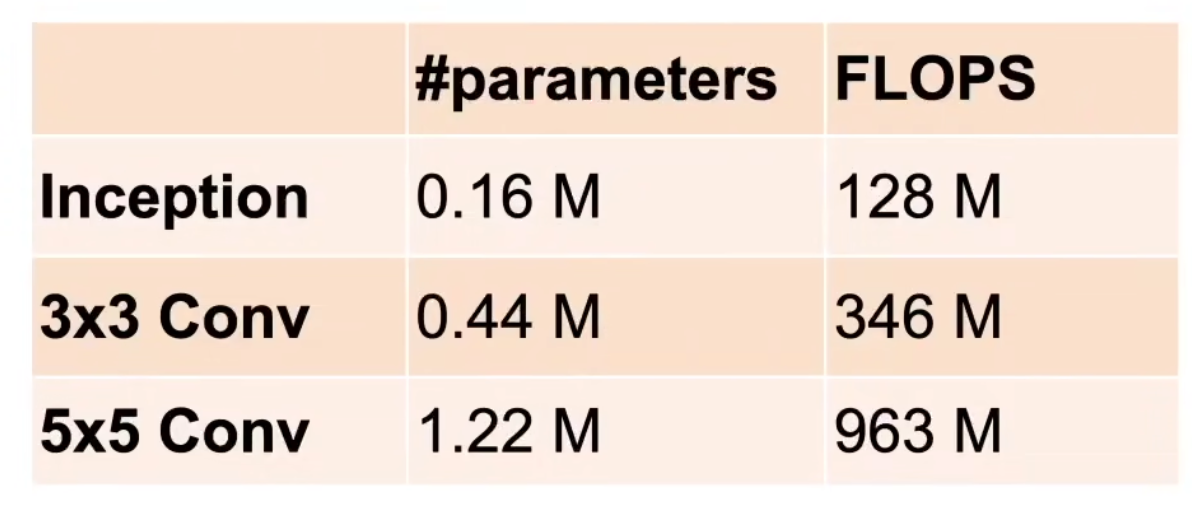
具体实现:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
- 注意这里用的是
cat,图像的维度是(批的大小,通道数,高,宽),这里dim=1表示按通道数堆叠在一起,不新增维度 6.4 多输入多输出通道#^97d15f - 和卷积层类似,这里定义 Inception 块时需要指定输入通道,四条路线的输出通道
2. GoogLeNet模型
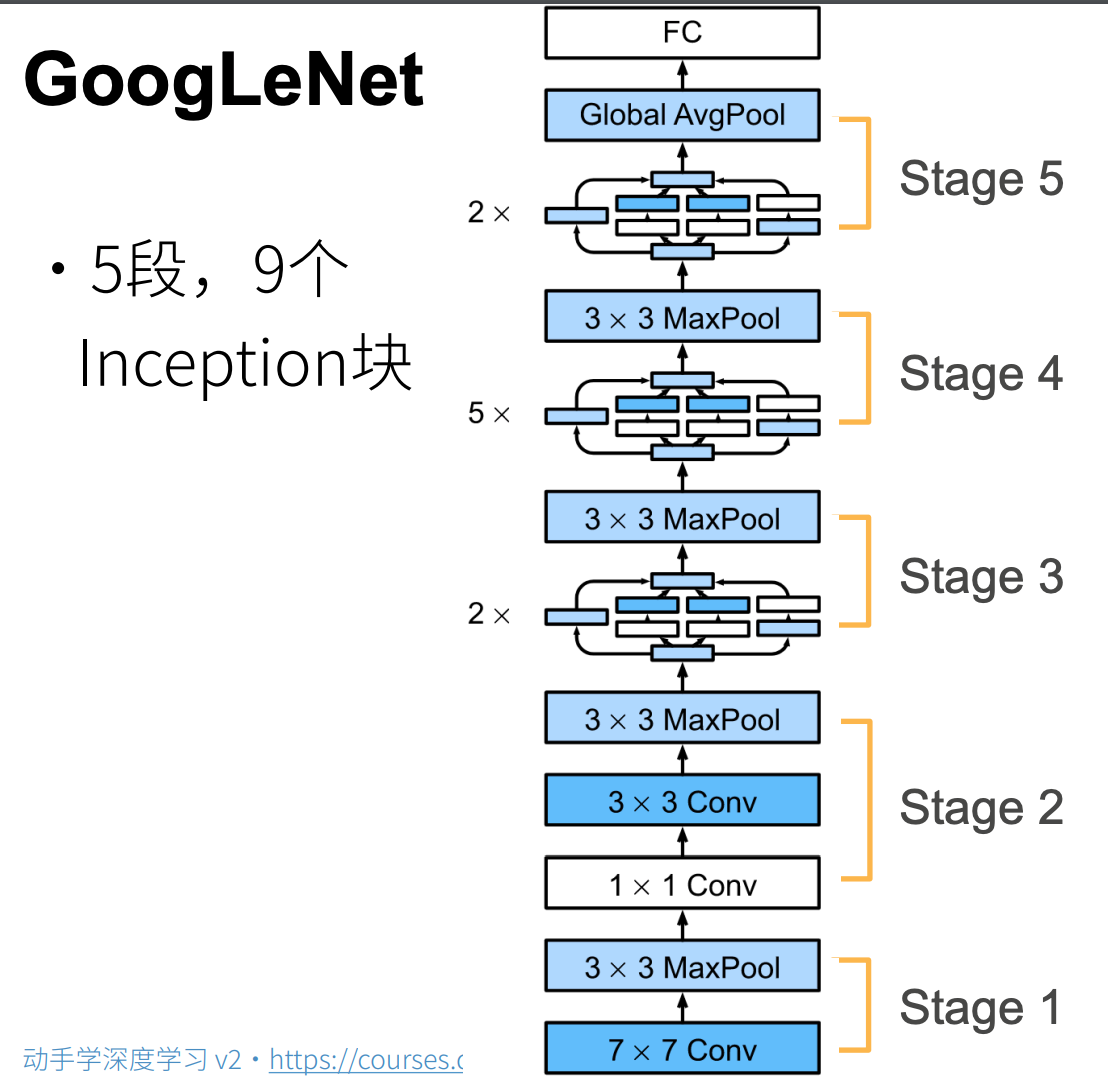
- 最后有一个 FC 全连接层,没有项 NiN 一样规定最后的通道数和类别数要一致
- 为什么是 5 个?和 VGG 一样的原因,7 除不下去了
2.1 Stage 1&2
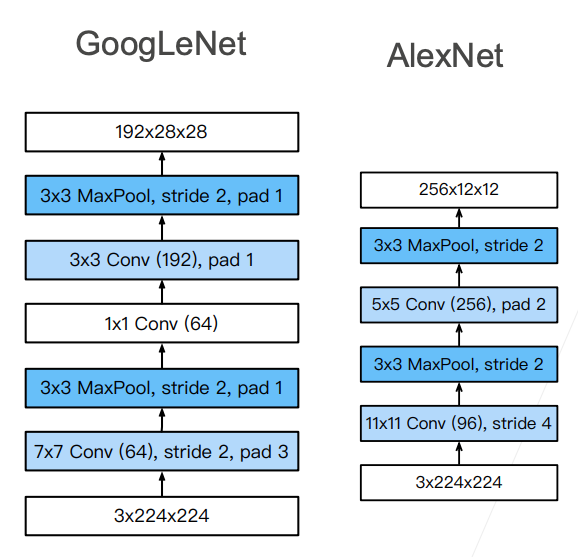
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
#这里用的是 fashion_mnist,输入通道是 1
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
2.2 Stage 3
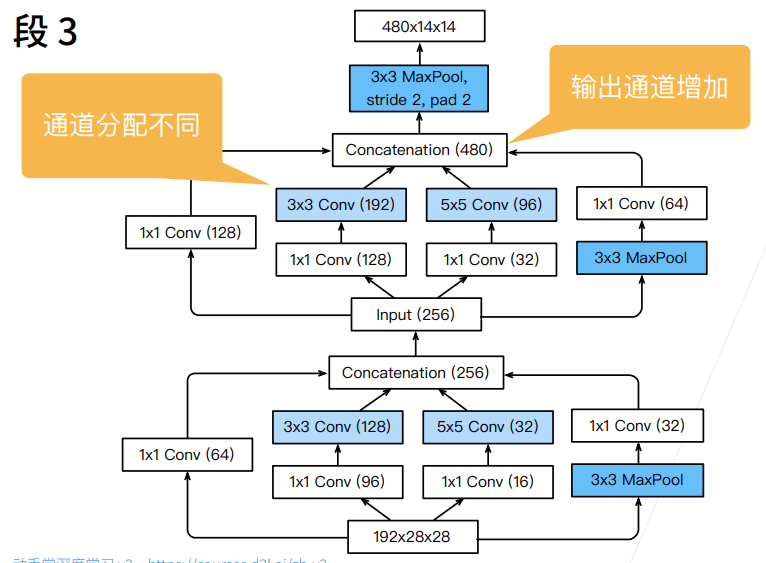
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
2.3 Stage 4&5
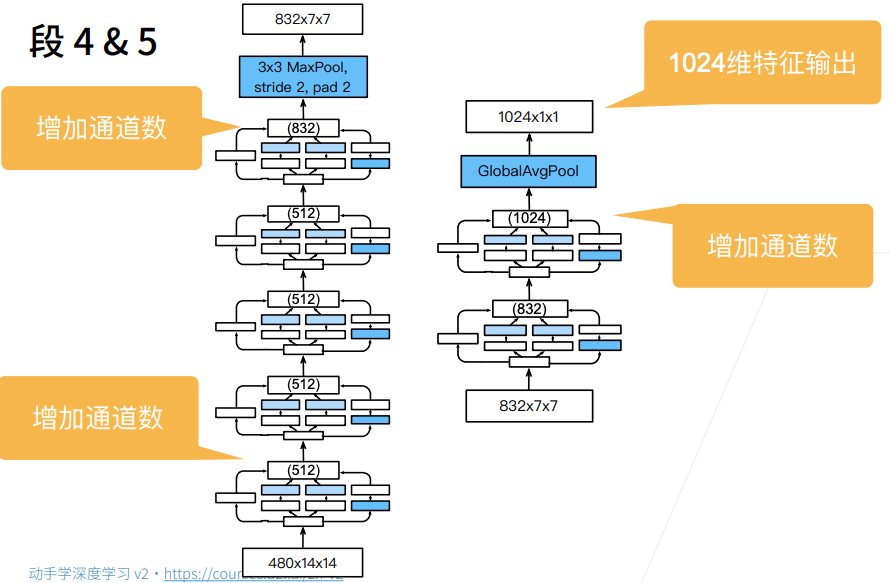
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten())
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
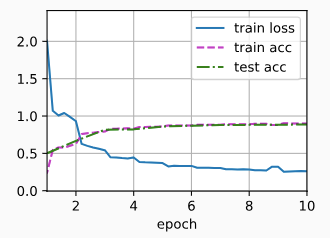
3 训练模型
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
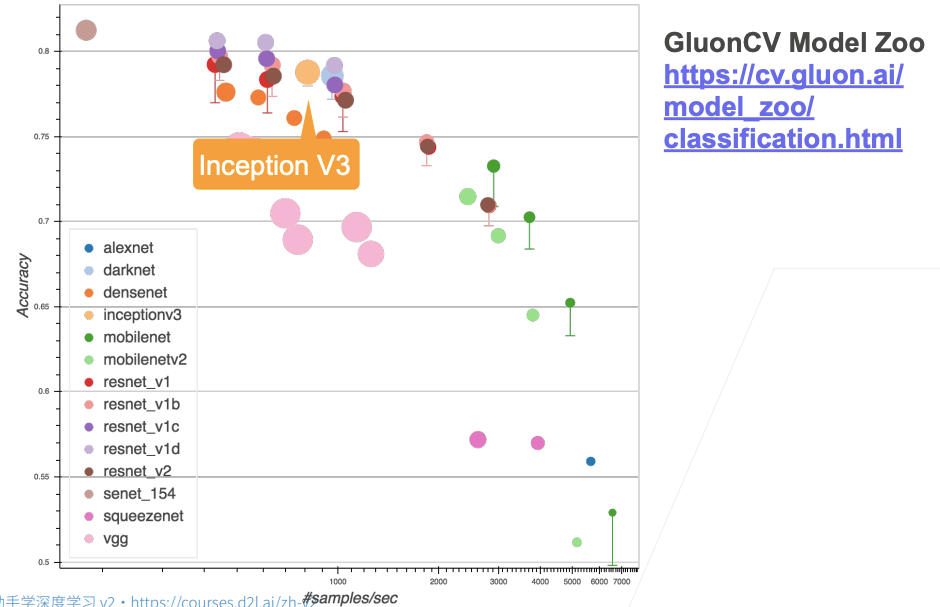
loss 0.262, train acc 0.900, test acc 0.886
3265.5 examples/sec on cuda:0
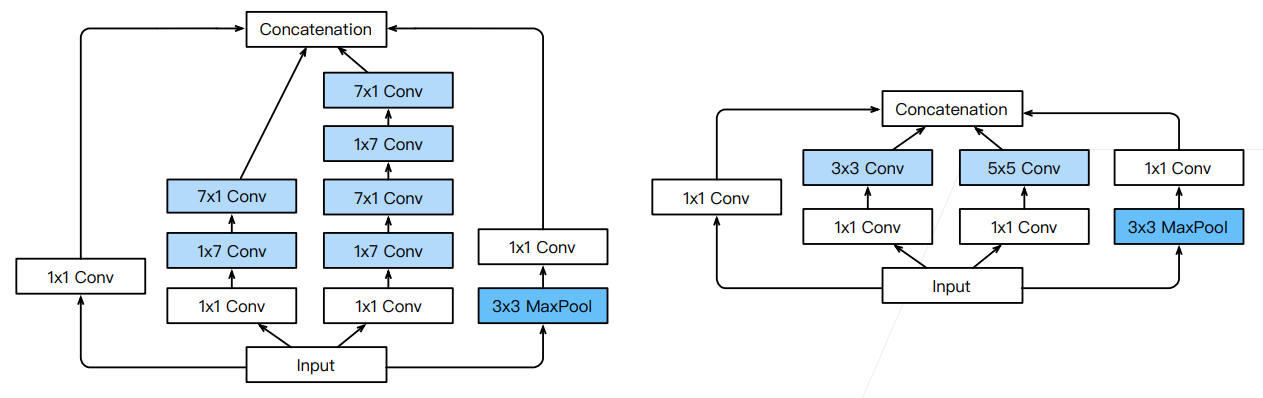
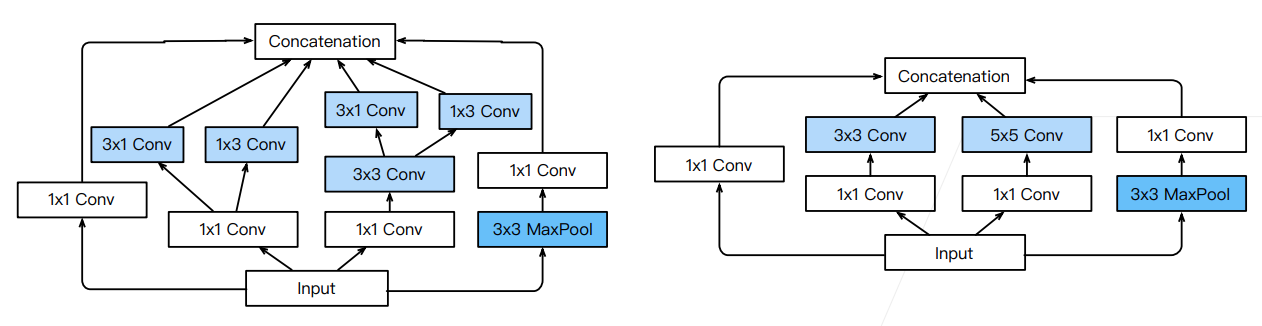
4. Inception 各种变种
- Inception-BN (v2) - 使用 batch normalization(后面介绍)
- Inception-V3 - 修改了 Inception 块
- 替换
为多个 卷积层 - 替换
为 和 卷积层 - 替换
为 和 卷积层(沿着宽学习一下,高学习一下) - 更深
- Inception-V4 - 使用残差连接(后面介绍)